Reasons why physical information processing resources in brains and computers are arranged in modular hierarchies
Electronic computing systems and brains can both perform huge numbers of different types of tasks. A personal computer can carry out user applications like browsing the internet; handling email; creating, editing and storing text, graphics and pictures; playing a wide range of games and so on. Other computers manage the internet, and control a wide range of physical systems like manufacturing lines, flight simulators or actual aircraft. A brain can perform many different types of cognitive tasks like speaking a language; recalling memories; playing games like chess, go or soccer; studying history, physics or financial management; riding a bicycle, playing a violin or cooking a meal, and so on.
The architectures of computer systems are constrained by the need to avoid excessive use of resources. Although the cost of one transistor is very small, if there were two system designs that could perform the same set of features, but one design required vastly more transistors than the other, the design with fewer transistors would be favoured. In principle each of the large number of applications run on a personal computer could be carried out on separate hardware, but this would require excessive resources. Somehow, resources must be shared between different applications. Similarly, natural selection will favour brains that require fewer resources like neurons. Somehow, there must be a degree of resource sharing between different cognitive processes.
MODULES: SHARED RESOURCES FOR SIMILAR INFORMATION PROCESSES In computing systems a lot of different information processes are required to carry out an application. Some of the processes needed to carry out different applications are similar to each other, in the sense that they could be performed on similar hardware. So the fundamental resource conservation approach is to identify groups of similar information processes across many applications. Processing resources are assigned to each group, and those resources optimized to perform the information processes in the group as efficiently as possible. The resource for each group is called a module. For example, a CPU module specializes in logic and arithmetic processes. A memory module specializes in processes for reading and writing data. A monitor interface module specializes in processes for controlling the pixels on a screen. A Wi-Fi module specializes in processes for sending and receiving information over a local wireless network and so on.
This can be taken a step further. There may be subgroups of the processes performed by a module that are even more similar to each other. The module hardware is therefore divided up into submodules optimized for each of these subgroups. In a further step, submodules may be divided up into sub-submodules and so on. The need to limit resources thus drives the existence of a modular hierarchy. At the top of the hierarchy are the CPU, memory, Wi-Fi interface etc. printed circuit assemblies. The submodules of the printed circuit assemblies include integrated circuits. Integrated circuits contain sections, sections contain cells, cells contain logic gates. Logic gates are made up of small groups of transistors. The existence of this modular hierarchy is driven by the need for resource economy, with high level modules performing different groups of similar information processes, and more detailed modules performing smaller groups of even more similar processes.
There is a further constraint on modules imposed by the need to perform at reasonable speed. If a module had to get most of the information it needed to carry out its processes from other modules, it would spend most of its processing time waiting for those other modules to generate the information. Hence modules must be defined in such a way that information exchange is minimized as far as possible. However, the more similar the information processes, the more likely such information exchange will be needed. The implication is that there will be much more information exchange within a module than between a module and its peer modules. This is exactly what we see in a computer system.
Yet another constraint on modules derives from the need to be able to manufacture large numbers of more or less identical copies of a computer system. If the manufacturing process is complex there is a high risk of errors. So a computer with a simple manufacturing process will have advantages over one with a more complex process. If all the modules on any one level were identical, the manufacturing process would be a lot simpler. However, the need to limit resources means that each module must be customized for a different group of information processes. As a result there is a compromise. Modules on one level are generally similar but have detailed differences. All integrated circuits look generally similar but internally there are differences.
Thus resource constraints drive the organization of computer hardware resources into a modular hierarchy with information exchange between modules minimized as far as possible. As I described in my blog last week, such a modular hierarchy is one of the key factors needed to support understanding of the computer system.
MODULES DON'T CORRESPOND WITH FEATURES However, achieving understanding is not trivial. Because the need to limit resources drives the modular hierarchy based on information process similarity, modules never correspond with applications or features as perceived by a user of the computer. Any one module on any level will provide processes to support many or all applications, and any application will need processes provided by many or all modules. Even at the most detailed level, if some transistors are involved in the performance of some widely used process like execution of one of the base CPU instructions, they will be active in almost every application.
WHY BRAINS HAVE MODULES ORGANIZED IN A HIERARCHY There are no direct resemblances between brains and computers. The information processes performed by the two types of system are qualitatively different. The information processes in computers are performed by transistors, the information processes in brains by neurons. However, brain architecture is subject to natural selection pressures. A brain with a certain amount of resources (like neurons) that can learn to perform a given set of behaviours will have a natural selection advantage over a brain that requires more resources to learn those same behaviours. For example, the less efficient brain will require more food and the brain must spend more time collecting that food leaving less time for other activities like reproduction.
The implication is that we can expect to see the brain organized into modules specializing in different types of information processes. We can expect to see submodules of the major modules, sub-submodules and so on. Because of selection pressures in favour of a relatively simple development process, we can expect that modules on one level will be generally similar but different in detail. We should be able to identify all these structures on the basis that there will be much more information exchange between the submodules of a module than between peer modules.
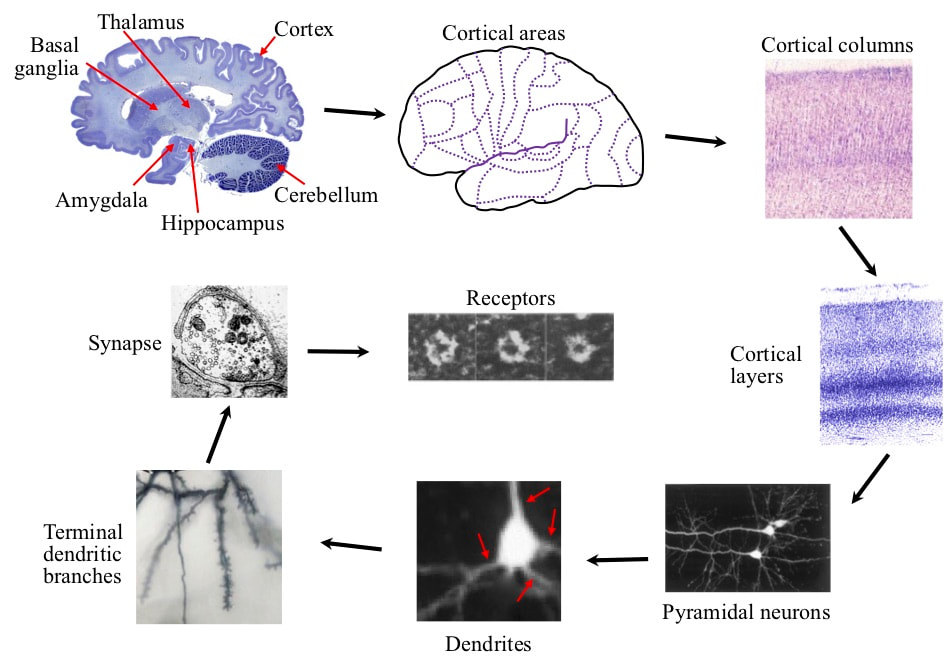
The organization of resources into a modular hierarchy of this type is clearly visible in the brain. Recall that the essential feature of modules is that there must be much more information exchange within a module on any level than between the module and its peer modules. Using the degree of connectivity as a proxy for information exchange, a hierarchy of modules is observed. The major brain modules are structures like the cortex, hippocampus, thalamus, basal ganglia, basal forebrain, amygdala, hypothalamus and cerebellum. There is much more connectivity within these structures than between them. For example, 99.7% of the output from cortical neurons goes to other cortical neurons, only 0.3% goes to subcortical structures. The cortex is divided into areas, with much more connectivity within an area than between areas. An area is divided up into columns with much more connectivity within a column than between columns. A column is divided up into layers with much more connectivity within a column-layer than between layers. a column-layer is divided up into pyramidal neurons with much more interaction within a neuron than between neurons. A neuron is divided up into dendrites with much more interaction within a dendrite than between dendrites. A dendrite is divided up into terminal branches with much more interaction within a branch than between branches.
BRAIN MODULES NEVER CORRESPOND WITH COGNITIVE FEATURES A module in the brain thus corresponds with a group of similar information processes. So any cognitive process will require processes performed by many modules, and all modules will support many different types of cognitive process. This is the reason that the search for anatomical modules that correspond with type of cognitive behaviour has been fruitless. For example, retrieving the memory for some past event involves activity in multiple cortical areas, plus the thalamus, basal ganglia, hippocampus, basal forebrain, amygdala, hypothalamus and cerebellum. In other words, activity in all the major structures. Then there are a number of cortical areas that are active in a wide range of different types of memory tasks....recalling events, remembering facts, and working memory tasks.
At one time it was argued that a cortical area in the fusiform cortex was a module supporting face recognition. However, lots of other areas are active during face recognition tasks. Furthermore, the area is also active when a bird expert is identifying the species of a specific bird or an expert on cars is identifying the make and year of a specific car. In addition, the recognition of written words also involves this area. Much of the time the visual objects we must distinguish between have quite different visual appearances. It is easy to tell the difference between a chair and clock. Different chairs are fairly similar, and different clocks are similar, but we rarely have to specifically identify many different chairs, or many individual clocks. However, human faces are all very similar objects, and we need to identify hundreds or even thousands of individual faces. Many birds are similar, and a bird expert must identify hundreds or even thousands of different species. Cars are similar, and a car expert must identify hundreds or even thousands of different models. Different written words can be very similar, but we are able to rapidly distinguish between thousands of different words. Thus this fusiform cortex area does not correspond with any one cognitive process. Rather, it performs the information processes needed to discriminate between large numbers of very similar visual images, when such discrimination is behaviourally important.
INFORMATION PROCESS TYPES The other prerequisite for creation of the hierarchies of description that make it possible to understand a complex control system is the use of common information processing concepts throughout the system. As I discussed in my previous blog, in the case of computer systems these concepts are instruction and data read/write. Next week I will discuss how some additional practical considerations drive the existence of these two specific types of process in computer systems, and how analogous practical considerations result in natural selection pressures in favour of information processes of two types in the brain, although the two types are qualitatively different from those in computers.